
Why do organisations engage in business intelligence and analytics (BI&A) activities? This seems such a mundane question when BI&A is one of the most talked about practices in the last decade. Given the numerous examples in academic and practice literature, organisations now understand the value of applying data-driven approaches to improve their business performance. And those that engage in this discipline are even more sought- after. In fact, Glassdoor’s annual ‘50 Best Jobs in America for 2017’ lists ‘data scientist’ in the top spot for the second year in a row!
Despite all this excitement, most organisations have failed to achieve widespread success in building their BI&A capability. While talent shortages may partly contribute to this, it is the organisational design aspect of the BI&A function that is the fundamental issue. Building a successful BI&A function is much more than just assembling a team of data scientists. It involves a three-step approach: First, aligning the perspectives of BI&A; then, fostering the right organisational climate; and finally, designing the function to enhance the capability to reduce equivocality and uncertainty in problem-solving.
Perspectives of BI&A
Perspectives matter. The way a BI&A function is designed and how it interacts with other functions within the organisation are determined, in part, by the way the business seniors and BI&A leaders perceive the practice of BI&A. BI&A can be perceived either as a data-oriented or as a decision-oriented practice. A data-oriented perspective of BI&A is one where the focus is on the transformation process from ‘data to information to insights to action’, leveraging both technology and techniques such as reporting, data mining, and predictive analytics to achieve it. On the other hand, a decision-oriented perspective of BI&A is one where the focus is on influencing the decision-making process and achieving business impact through the generation and execution of data-driven insights. This classification finds support in practice literature where the discipline of BI&A can be viewed through the lens of data science versus decision science.
To illustrate this, consider a situation where a BI&A practitioner has been asked to reduce the occurrence of customer fraud in a bank. The practitioner with a data-oriented perspective would focus on account usage data that would indicate a fraud activity has taken place and attempt to develop a predictive model for future instances. The practitioner with a decision-oriented perspective would focus on the current process of fraud identification and resolution. How does it get detected (what information triggers it), when does it get detected, who detects it, what information is utilised to confirm it, what decisions are eventually taken to resolve it, what is the financial value of detecting it in advance, and when is the peak financial impact of the fraud activity. There are clearly a lot of different types of data that needs to be assembled that are contextual to each nexus of fraud detection and decision-making in the latter perspective, and the BI&A practitioner may eventually land on a solution that is multistaged and layered, and perhaps predicting an upstream precursor of the fraud event rather than predicting the fraud event itself.
Having both business seniors and BI&A leaders synchronise on a decision-oriented perspective is a necessary starting foundation towards developing a successful BI&A function. Mismatched perspectives between BI&A leaders and their respective business stakeholders can give rise to potential conflicts of expectations, and result in the sub-optimal performance of the BI&A function due to misaligned engagements.
Organisational climate
Achieving an aligned decision-centric perspective between BI&A practitioners and their business stakeholders starts with having the right organisational ‘climate’ that is shaped by senior management influences. In his 2006 Harvard Business Review article, ‘Competing on Analytics’, Thomas H. Davenport, a senior adviser at Deloitte Analytics, suggests that senior management advocates are an important factor to achieving success in implementing an analytically-oriented culture across an organisation. Many successful companies have CEOs who are chief analytics advocates. This ‘tone from the top’ can be expressed as three climate requirements:
1. Senior management asking for facts and evidence to justify any proposed or implemented decisions,
2. Ensuring that those facts and evidence are independently corroborated by the BI&A function, and
3. Raising the visibility and profile of the BI&A function by having the leadership team of the BI&A function actively participate in decision-making meetings.
Working in concert, these three requirements drive a decision-oriented culture within the organisation. The BI&A function becomes cognizant of the decisions looming on the horizon and is able to partner with business stakeholders to focus attention on utilising data to help make better decisions rather than focusing on data capture and accumulation.
Functional design
So how should one go about designing the BI&A function? Core to the design considerations is the BI&A function’s capability and capacity to reduce uncertainty and equivocality in decision-making. The notion of ambiguity, equivocality and uncertainty are central themes in problem-framing and problem-solving. But what do these terms mean? Stated simply, ambiguity is the inability to make sense of something, while equivocality is the ability to make sense of something where different interpretations exist, and uncertainty is a lack of sufficient information to describe the current state or predict a future state of something. There is a natural hierarchy at play here. Ambiguity resolves to equivocality as the interpretative void gets filled with multiple interpretations. Narrowing these multiple interpretations and hypotheses leads to a convergence of the problem statement, with only uncertainty remaining. And, when only uncertainty remains, then the task of closing that gap with data becomes obvious. Figure 1 summarises the relationship of convergence from ambiguity to uncertainty.
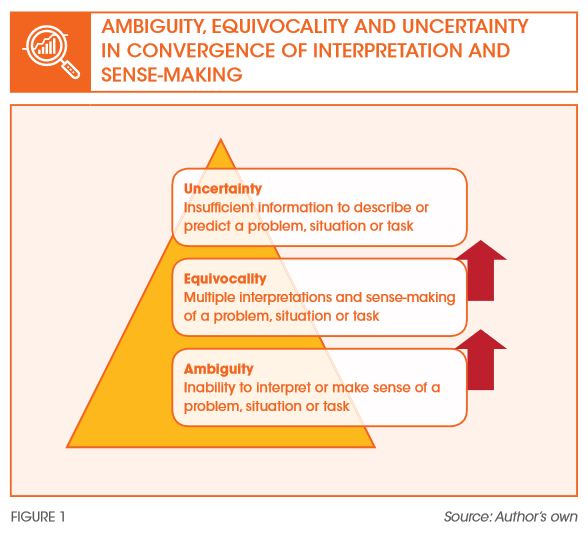
To better illustrate the differences among ambiguity, equivocality and uncertainty, consider a typical situation where a company is seeking to expand regionally in step with the competition. At the start, things are pretty ambiguous as the company seeks to articulate clear objectives for its expansionary goals beyond just ‘keeping up with the Joneses’. Management soon converges on the objective to expand into markets with significant growth opportunities and acceptable risks. However, it is still unclear as to the explicit definition of growth and risk. Does the company define growth as compound annual growth rate of profits over the next three years? And similarly, should they define risk as the forecasted number of competitors over the next 10 years in those regional markets, or perhaps the expected tightening of industry regulations and its impact over the next two years? The situation is clearly equivocal. At some point, the company converges on the agreed definitions for growth and risk, and the task now focuses on how best to go about collecting or ‘proxy-ing’ the data for the agreed definitions. The problem now reduces to a state of uncertainty.
Many organisations, and even BI&A practitioners, believe that their work involves solving uncertain problems—finding and mining data to validate hypotheses and generate insights. They fail to see that the problems they confront are many a time highly equivocal because data can take on different meanings when placed in different contexts and when viewed through different experiential lens. The failure to recognise these differences in problem-framing and problem-solving has led to organisations achieving limited success in their BI&A efforts.
Figure 2 depicts a deconstructive framework for BI&A-driven problem-solving. For BI&A activities to commence, a business problem needs to be translated into a data problem. For example, if the business problem is acute customer attrition, translating it into a data problem implies finding the appropriate collection of data that is associated with the attrition phenomenon such as customer demographics, product pricing, offers from competition and product usage. Once the data has been assembled, the BI&A function then performs a variety of data mining techniques to prove or disprove hypotheses and generate incremental insights and translate that into a data-driven output such as a prediction or forecast model or a classification (i.e. segmentation) model. This represents the data solution stage. The data solution then needs to be further integrated into the day-to-day operating process of the organisation for final implementation and execution. For example, a customer attrition prediction model would need to be translated into a customer retention campaign with the appropriate resources and marketing offers to support it. This represents the translation of a data solution into a business solution.
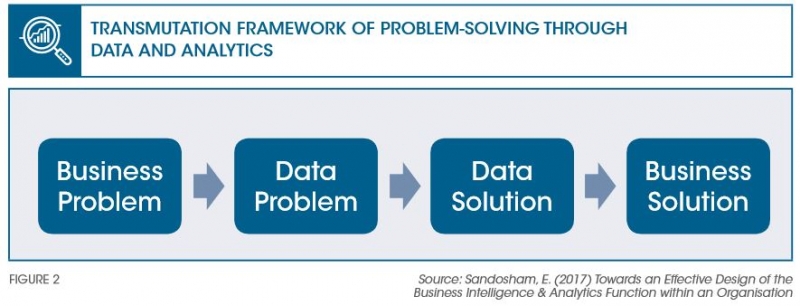
Translating a business problem into a data problem can be subjective, akin to problem-framing. This subjectivity is a source of equivocality and ambiguity in BI&A work. Equivocality occurs because of the different lens that are applied in the initial interpretation of a business problem or business phenomenon (consider the earlier example of a company expanding regionally). Translating a data problem into a data solution is primarily about reducing uncertainty. And finally, translating a data solution into a business solution, too, is high in equivocality as it requires familiarity with both the business domain and the business operating processes to achieve success.
The role of the integrator
Typically, the activities within a BI&A function can be demarcated into two major categories—Data & Information Sense-Making, and Data & Information Management. Data & Information Sense-Making is akin to the collective BI&A activity of translating a business problem into a data problem, and translating a data problem into a data solution. Data & Information Management is akin to translating a data solution into a business solution.
Data & Information Sense-Making includes data mining, campaign design, experimental design, segmentation modelling, predictive modelling and optimisation modelling. These activities are less routine and less repeatable and are obviously more equivocal in nature. Data & Information Management includes activities such as data preparation, data quality assurance, information reporting, campaign execution and fulfilment, model validation and maintenance. These activities are characterised by their routine and repeatable nature; they are highly procedure- or rule-oriented. Now, conversations with BI&A practitioners and business stakeholders confirm that higher business value is generated through Data & Information Sense- Making activities.
Organisations where the BI&A resources handle Data & Information Management contiguously with Data & Information Sense-Making are defined as Generalist models. On the opposite end of the spectrum, organisations that have a clear separation of BI&A resources handling Data & Information Sense-Making versus Data & Information Management are defined as Specialist models.
The choice of Generalist or Specialist organisational model is intimately related to the overall level of BI&A maturity within the organisation, and more specifically, to the level of maturity and sophistication of the BI&A function. Most BI&A functions adopt a Generalist model when they first begin. However, they soon realise two things. First, that the Data & Information Management activities consume a disproportionately larger percentage of the BI&A resources, leaving little room for the BI&A function to develop their Data & Information Sense-Making capabilities. Second, the skillsets and competencies needed for Data & Information Management and Data & Information Sense-Making activities are quite different and not altogether interchangeable.
A significant percentage of Data & Information Sense-Making activities is about reducing equivocality. To achieve this, the BI&A function needs to increase its context-specific business domain expertise. This can be achieved with the introduction of the Integrator role. The Integrator is the primary person within the BI&A function to translate a business problem into a data problem. The Integrator seeks convergence of the various perspectives of the problem statement through iterative discussions with the business stakeholders. The Integrator could be the head of the BI&A function (for smaller functions) or a senior member of the BI&A team. Seniority is clearly a requirement as the person must be able to interact with senior stakeholders/ decision-makers and possess sufficient business domain knowledge and business experience to recognise the equivocality of a business challenge, and to translate it effectively into a data problem.
The introduction of the Integrator role usually goes hand-in-hand with a move towards the Specialist model where the Data & Information Sense-Making activities are explicitly separated out with dedicated full-time BI&A resources. This move increases the discussions and interactions between the business stakeholders and the BI&A function around current and pertinent business challenges and thus increases the BI&A function’s capability to deal with problems of an equivocal nature.
For larger organisations, the BI&A resources within Data & Information Sense-Making are composed of one or more ‘talent pods’. Each talent pod is a grouping of BI&A resources to support one or more lines of business. Heading up each of these talent pods is an Integrator. Talent pods often attend meetings together thereby reducing fidelity loss in information transmission. A talent pod allows context-specific domain knowledge to be retained and ‘institutionalised’ within the team, speeding up the process of problem recognition within the pod. As the BI&A function continues to mature, the use of advanced modelling techniques becomes increasingly important. Predictive modelling is a common and valuable pursuit in solving uncertain problems, and some BI&A functions create dedicated resources to support such activities.
Proximity
Organisational proximity, as well as physical proximity, is an important consideration in addressing equivocality. Organisational proximity is about how ‘near to the top’ the BI&A leader is in a reporting structure. Physical proximity is about how ‘near to the business stakeholders’ the BI&A function is. The more proximal the BI&A function is to these two aspects, the higher the capability the function has in addressing equivocal problems. The reason being that equivocality can be reduced through having access to business context, the richness (face-to-face) and greater frequency of interactions with stakeholders, the higher fidelity of information transmission, and the ability to build trust and relationships.
In a rush to create the BI&A function, many organisations take the route of consolidating and aggregating their BI&A-related resources into a single location, citing the ‘centre of excellence’ or ‘centre of competency’ strategies. Such approaches would typically reduce the capability of the BI&A function to address equivocality problems as the function becomes isolated from the lines of business that it supports.
Collaboration
Although translating a data problem into a data solution can be fraught with equivocality, it is primarily an uncertainty reduction activity. It would seem intuitive that by pooling BI&A resources together, i.e., through centralisation, the amount of data and information available to the BI&A function would increase, and the capability to reduce uncertainty will also correspondingly increase. However, this may not always be true. One key insight is that the acquisition of more information (i.e., data that has been interpreted or placed into context) is driven by the types of internal partnerships to gain access to data. Internal data resides within the organisation’s operating systems and requires IT support to extract and curate it for use by the BI&A function. The BI&A function’s perspective of data is different from that of IT. As such, many BI&A functions create their own intermediate or surrogate IT team, both to support their internal BI&A requirements, as well as to interface and work closely with the main IT function. Therefore, to expand and enhance a BI&A function’s ability to deal with uncertain problems, one should cultivate a strong partnership and collaboration with one’s internal IT function.
Appetite for experimentation
Another key insight is the ability of the BI&A function to create new information, i.e., contextualised data through experimentation. An experiment is simply the execution of a well-designed test to collect contextualised data to either validate a set of hypotheses, or to shed incremental insights into a phenomenon that is not well understood, or which has insufficient data with which to construct an understanding. The BI&A function needs to have the technical skills to design experiments to collect unbiased data and the infrastructural ability to execute it. Running experiments consumes time and effort and engenders the possibility of losing profit opportunities due to delays. Not all business stakeholders have the proclivity or appetite for experiments in the face of profit pressures.
Offshoring
The insights on proximity and collaboration lead us to another key insight—offshoring. While cost arbitrage is cited as a key driver for offshoring, the choice of geographic location is also based on availability of talent. However, the bulk of BI&A activities that are being offshored relate to data preparation and reporting. The common thread of these offshored activities is that they are unambiguous and repeatable; the term ‘low value’ is often used to describe these activities. But the offshore talent hired to perform these activities usually seem disproportionately highly-skilled, with many having postgraduate degrees in STEM (science, technology, engineering and mathematics) subjects. The lack of proximity to the business stakeholders and the decision-making process is cited as a key obstacle to offshoring higher value (and more equivocal) work—the offshore talent rarely has direct interaction with the onshore business stakeholders. This mismatch of expectations for hired offshore talent seems obvious and may be a contributing factor to the higher talent attrition rate commonly cited for these locations.
Data, data, and more data
And so we ultimately circle back to the fundamental question, “Why do organisations engage in BI&A activities?” The answer is simple. They do so to improve the speed and quality of decisions by reducing uncertainty and equivocality through the use of data-driven solutions and insights. This expanded answer provides a much needed fresh perspective to organising BI&A activities by understanding the purpose of BI&A activities—improving decision-making—and the pathway to achieving that purpose—reducing uncertainty and equivocality.